
Para optimizar cualquier aplicación o sistema de información, es importante saber como esta diseñada para medirlo, ejecutando herramientas externas que permitan chequear los componentes y tener métricas para trazar una linea base de referencia antes de realizar ningún cambio.
Nuestro primer objetivo es conocer con exactitud «el paciente», sus principales “constantes vitales” y el «estado de salud» del sistema en producción, es como, si vamos al médico y lo primero que nos toman es la temperatura y la tensión. Si pasamos de 37º o tensión alta automáticamente se disparan las alarmas médicas y nos empiezan a mirar con más detalle para detectar cual es el origen del problema y buscar el mejor tratamiento para solucionarlo.
Aplicaciones y Transacciones de negocio
Hay que elegir que aplicaciones, transacciones, middleware, servicios y bases de datos se van a investigar para implementar el monitoreo y herramientas para cada una de ellas como saber reconocer que existen diferentes estrategias en aplicaciones .Net, Java, Php,etc y el monitoreo estará enfocado en los objetivos, especialmente de la recopilación de datos.
Topologia y Escalabilidad
Aunque esta fuera del alcance del artículo, es importante conocer la arquitectura física y topologia de red donde corre la aplicación como los tipos de balanceadores de carga y gateways que se estan utilizando para la escalabidad horizontal o vertical del sistema en producción.
- Balanceadores hardware: Son dispositivos físicos ya optimizados y listos para utilizarse que soportan hasta 30 Gbps.
- Balanceadores virtuales: Una solución de software que se monta sobre máquinas virtuales de VMware, Hyper-V, KVM, Xen y VirtualBox.
- Balanceadores en Nube: Son balanceadores para implementaciones en la nube y entornos híbridos. Como Azure, Amazon AWS, Google Cloud.
- Balanceadores Bare Metal: Soluciones software ejecutadas “sobre el metal”, sin capas intermedias. Permiten convertir un servidor existente en un balanceador de cargar de alto rendimiento.
En resumen, debemos ser capaces de responder a preguntas como estas:
- Como recopilar y retener la infomación y datos obtenidos para el estudio?
- En condiciones normales ¿Cuanto tarda una página?, digamos 1 segundo.
- En condiciones de mucha carga, ¿Cuanto tardará?, pongamos 30 segundos.
- En sistemas con escalabilidad vertical: Si con un hardware X tengo una tiempo T, ¿con un hardware 2X consigo 2T (el doble de tiempo de respuesta)?
- En sistemas con escalabilidad horizontal: Si con X servidores tengo una capacidad de respuesta T, ¿Con 2X servidores tendré un tiempo de respuesta 2T?
- PREGUNTA CLAVE: ¿Es aceptable/SLA del servicio de 5,10,20,30 segundos?
Conociendo el sistema en producción
- Arquitectura «monilítico/client-server/distribuido/brokers/etc».
- Funcionamiento “Request/Response”, «Publish/subscribe», «Queues», etc.
- Cuantos visitantes recibe el sitio en 24 horas (determinar la hora de más tráfico)
- Cuantas páginas de media se visitan en 24 horas (determinar la media más alta)
- Tiempo de realizar una transacción: timestamp inicio y fin
- Estadísticas de uso por aplicación, por horas, por usuario
Veamos un ejemplo de como empezar a valorar y medir un sistema para calcular una métrica de referencia, por ejemplo, 10.000 visitantes/dia y 5 paginas vistas/visitante
- 10.000 visitantes x 5 páginas = 50.000 páginas/día
- 50.000 / 24H = 2.083 páginas/hora (24h generalmente la noche hay poco tráfico)
- 50.000 / 12H = 4.166 páginas/hora (12h nos dará una media más exacta)
- 4.166 / 60 = 69,4 páginas/minuto
- 69,4 / 60 = 1,15 páginas/segundo
Solo con esta simple estimación, vemos que no es un problema de escalabilidad, ya que, si el sistema no es capaz de servir 1,15 pag/segundo es que tenemos un problema gordo (bottlenecks) que esta causando que el sitio no responda como deberia.
Causas generales que pueden provocar pérdidas de rendimiento
- Aplicar services packs en aplicaciones o sistemas incorrectamente
- Realizar cambios de hardware, virtualizaciones, cloud
- Configuraciones de antivirus, firewalls, routers, reglas, cableado, etc
-
Cambios o migraciones de sistema operativo de servidor
- Cambios o migraciones de versiones IIS, Apache,SQL,Oracle,etc
- Integraciones con otros sistemas como BigData, ESB, PayPal, etc
- Mal uso de frameworks ORMs en las aplicaciones
-
Grandes incrementos de datos en las bases de datos
-
SELECTs mal diseñadas que tardan mucho en producción
- Falta de Tunning y revisión de planes de ejecucion en BBDD
- Transacciones, bloqueos, deadlocks, triggers, etc en BBDD
- Repartir carga de trabajo entre varios servidores
- Realizar peticiones sincronas entre sistemas con mucho tráfico
- Peticiones muy pesadas que pueden provocar cuellos de botella
- Otras causas que podemos encontrar cuando investigamos
Causas en Balanceadores que pueden provocar problemas (sondeos, rutas, nsg)
- Los tiempos de respuesta son lentos
- La aplicación es inaccesible por los usuarios
- No se puede acceder a las VMs de la aplicación
- Se agota el tiempo de espera de las solicitudes de los usuarios
- Configuración de sondeo incorrecta, como una dirección URL o un puerto incorrectos
- Un firewall o NSG de red que bloquea puertos o direcciones IP que usa la aplicación
- VMs no responde al sondeo porque el puerto requerido no está abierto en NSG
- VMs fuera de servicio o no responde. Es posible que la VM esté deshabilitada
- VMs erróneas o con incidencia de seguridad, como un certificado expirado en el servidor
- VMs podrían estar sobrecargadas, la aplicación escucha en un puerto incorrecto o la aplicación se bloquea.
Herramientas que podemos utilizar para diagnosticar probemas
- Aplicacion Debug y Trazas (debug,trace,logs,fiddler,IntelliTrace)
- Contadores de Rendimientos (asp.net, wcf, net fw, etc)
- Depuradores en producción (remoting debugging)
- Profilers de memoria y rendimiento (ANTS, dotNetTrace, etc)
- Dashboard y Reportings DataBases (sqlserver,oracle,…)
- Visor de Eventos y seguimiento (nivel y politicas de traza)
- APM Tools: AlertSite, AppDynamics, AppInsights, DynaTrace, NewRelic, etc.
- RUM Tools: What is Real User Monitoring
Que debemos tener en cuenta en aplicaciones web/distribuidas
- performance monitor: cpu, ram, red, disco, counters E/S
- páginas web: imagenes, videos, js, css, bundle, etc
- sprites: para cargar conjuntos de images, iconos no de forma individual.
- navegador cliente: cache, expires, etag, etc.
- server web: modulos, handlers, websockets, pools, framewoks
- server web: recomendable 1 estático + 1 dinámico
- base datos: análisis, rendimiento, index, selects mas costosas.
- HA proxy-cache: varnish, front-end NLB
- HA memcache, redis, rabbit-mq
- medir: users, peticiones, conexiones, threads
- tools: page speed, yahoo yslow, etc
Recordatorio: Siempre debemos medir el rendimiento antes y después de los cambios.
GTMETIX – Por donde empezar una optimización Web
Lo que yo recomiendo es crear una cuenta GTmetrix, es gratis y empezar a trabajar con esta herramienta para optimizar nuestras web: https://gtmetrix.com
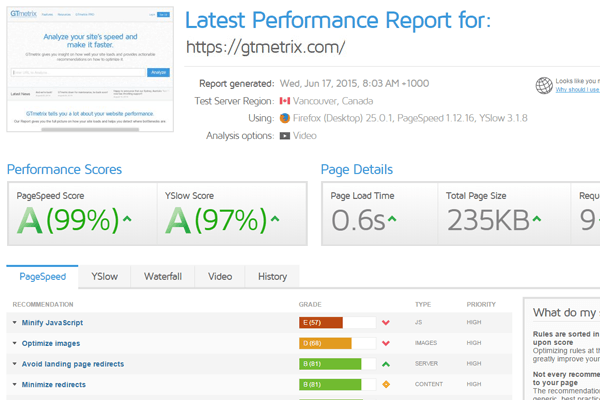
Simplemente, poner la URL de vuestro sitio web y pulsar botón, para una primera valoración del estado de nuestra aplicación web, ya nos sirve y seguro que detectará unos cuantos problemas en el informe y que podéis imprimir en pdf. También podéis lanzarla sobre la web de Google por ejemplo para hacer una comparativa.
Importante: Si no estáis registrados (gratis) las peticiones se lanzan desde «Canada» y la performance os puede confundir, con la cuenta registrada podemos configurar la herramienta para hacer las peticiones desde Europa, actualmente dispone de la opción London (UK), para ello, hay que configurar la herramienta y si queremos unos test más exactos, también podemos configurar la velocidad de la conexión y otros factores.
A partir de aquí, analizar los resultados de PageSpeed, YSlow, Waterfall y empezar a corregir los problemas detectados poco a poco y volviendo a lanzar la herramienta para ver los tiempos de mejora obtenidos.
FAST OR SLOW – Midiendo una Web desde varios paises
Fast or Slow es una herramienta online para medir el rendimiento global de un sitio web que detecta e informa sobre los factores más importantes en la experiencia de los usuarios ofreciendo informes y varias métricas de forma automática.

Para empezar: https://www.fastorslow.com
LocaBrowser – Probar Webs geolocalizadas
Esta herramienta permite probar sitios web geolocalizados desde distintos lugares en tiempo real solo con introducir el sitio web y seleccionar un país.

Para empezar: https://www.locabrowser.com
Mozilla Observatory Scan
Es una utilidad online para analizar sitios web para enseñar a los desarrolladores, admins y profesionales de seguridad cómo configurar sus sitios de manera segura.
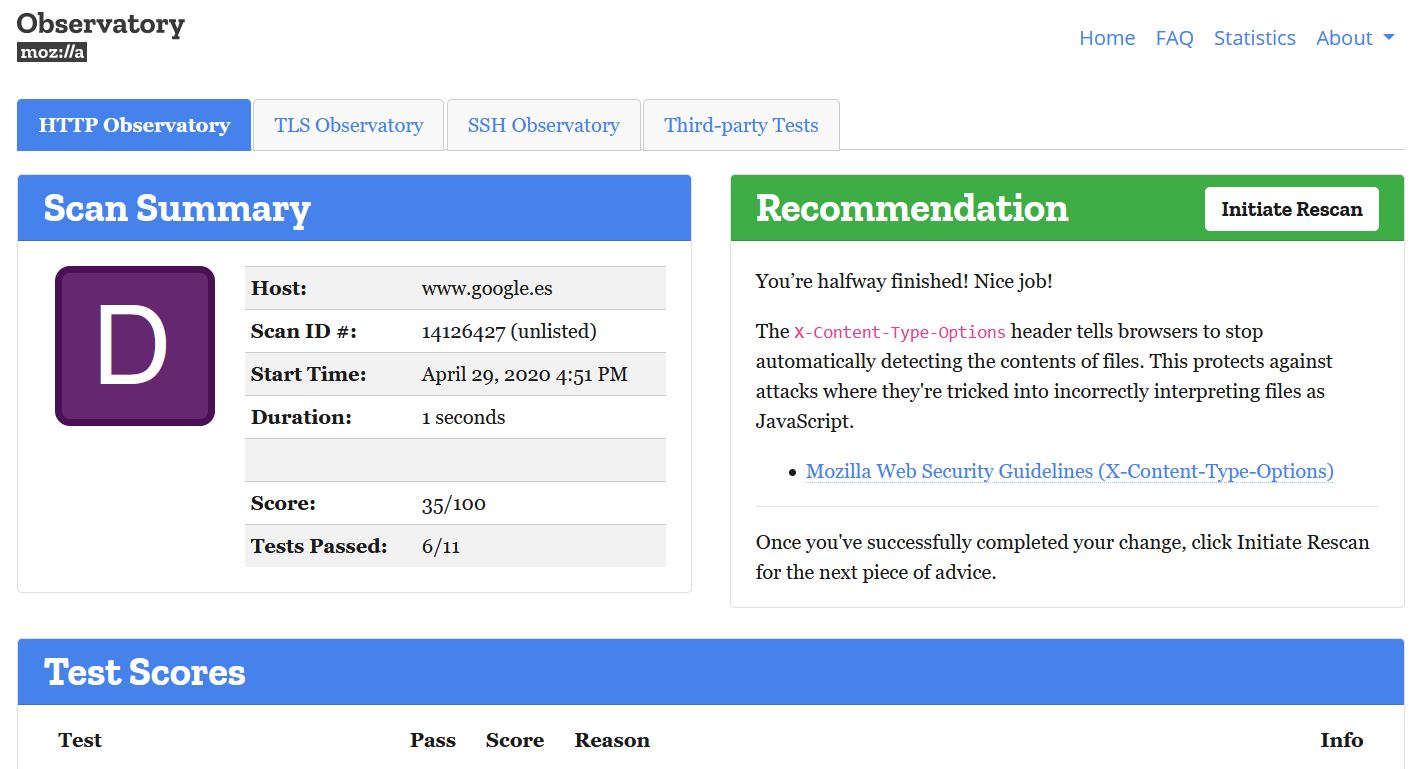
Para empezar: https://observatory.mozilla.org
APPDYNAMICS – Topología y Transacciones de negocio
Esta herramienta es un APM de pago genial para monitorizar grandes infraestructuras y redes de forma que podamos detectar cuellos de botella en las transacciones, llamada de base de datos, alertas, analisis de datos, etc.

Uno de los mejores APM del mercado, lo he utilizado últimamente y permite descubrir mucha información de forma rápida, intuitiva, «simplemente» configurando agentes en las máquinas que vamos a monitorizar, eso si, es de pago y requiere licencia por cada nodo. En escenarios complejos es una herramienta imprescindible para detectar cuellos de botella en todos los puntos críticos de los sistemas de información.
Para empezar: https://www.appdynamics.com
![]()
Apache JMeter es una aplicación Java que se puede ejecutar en Linux, Mac y PC y permite probar el rendimiento de páginas web y recursos estáticos y dinámicos, incluidos los servicios web, ASP.NET, Java, PHP, bases de datos y consultas.
Podemos usarlo para simular una gran carga en un servidor, grupo de servidores, red y hacer un análisis gráfico del rendimiento o para probar su comportamiento de servidor / script / objeto bajo una gran carga simultánea.
- Web – HTTP, HTTPS
- SOAP / REST
- FTP
- Database via JDBC
- LDAP
- Message-oriented middleware (MOM) via JMS
- Mail – SMTP(S), POP3(S) and IMAP(S)
- Native commands or shell scripts
- TCP
Para empezar con ello: Apache JMeter
Otras herramientas OpenSource
Recopilatorio de herramientas súper útiles para medir performance.
Artillery: https://artillery.io/docs/getting-started/
Install: $ npm install -g artillery
Ejemplo: $ artillery quick -r 500 -d 120 http://google.com
Bombardier: https://github.com/codesenberg/bombardier
Install: $go get -u github.com/codesenberg/bombardier Ejemplo: $ bombardier-c 125 -n 10000000 http://google.com
PowerShell: Copiar en un archivo.ps1 y ejecutarlo según necesidades:
Write-Output "Prueba: Enviando peticion GET 100 veces"
for ($i = 0; $i -lt 100; $i++) {
Invoke-WebRequest -Uri https://<ip-url>/api/values -Method 'Get'
}
Si conoceis otras herramientas interesantes dejarlas en los comentarios 🙂
